推理 优化 #
overview[2] #
有几种方法可以在内存中降低推理成本或/和加快推理速度。
- 应用各种并行处理方式,以在大量GPU上扩展模型。智能并行处理模型组件和数据使得运行拥有数万亿参数的模型成为可能。
- 内存卸载,将临时未使用的数据卸载到CPU,并在以后需要时再读回。这有助于减少内存使用,但会导致更高的延迟。
- 智能批处理策略;例如,EffectiveTransformer将连续的序列打包在一起,以消除批处理内的填充。
- 网络压缩技术,如修剪、量化、蒸馏。较小的模型,无论是参数数量还是位宽,应该需要更少的内存并且运行更快。
- 针对目标模型架构的特定改进。许多架构变化,特别是针对注意力层的变化,有助于提高Transformer解码速度。
模型压缩 [1] #
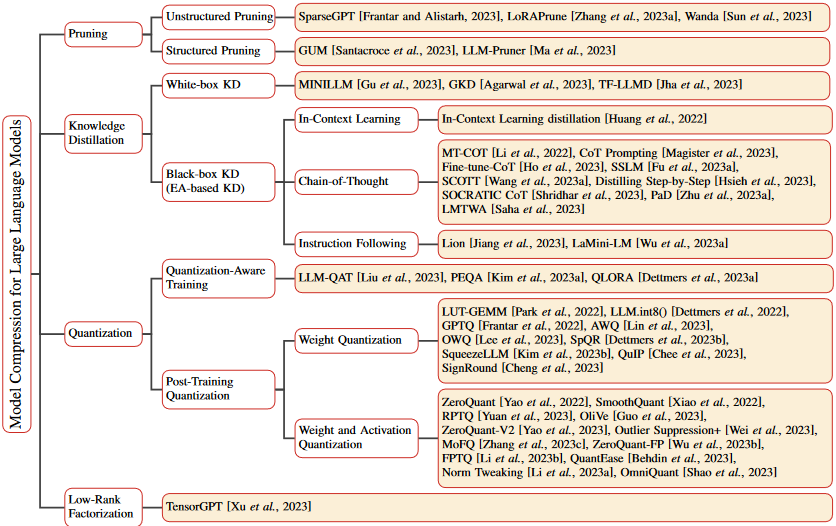
- 剪枝(Pruning)
- 知识蒸馏(Knowledge Distillation,KD)
- 量化(Quantization)
- 低秩分解(Low-Rank Factorization)
KV Cache #
参考 #
综述 #
1xx. NLP(十八):LLM 的推理优化技术纵览 ***
1xx. 大语言模型推理性能优化综述