论文[Foundational Models Defining] #
- 论文地址 《Foundational Models Defining a New Era in Vision: A Survey and Outlook》大学
基础模型分类 [1] #
- 分类 {% asset_img ’’ %}
- 分类 {% asset_img ’’ %}
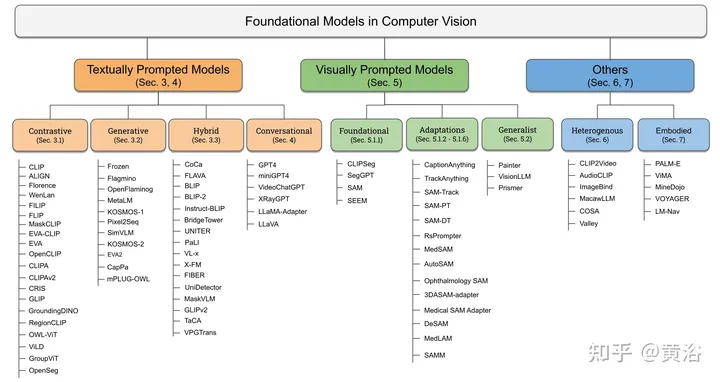
textually prompted models #
- contrastive CLIP 双塔
- generative Flamingo
- hybrid BLIP
- conversational GPT-4, miniGPT4, LLaVa
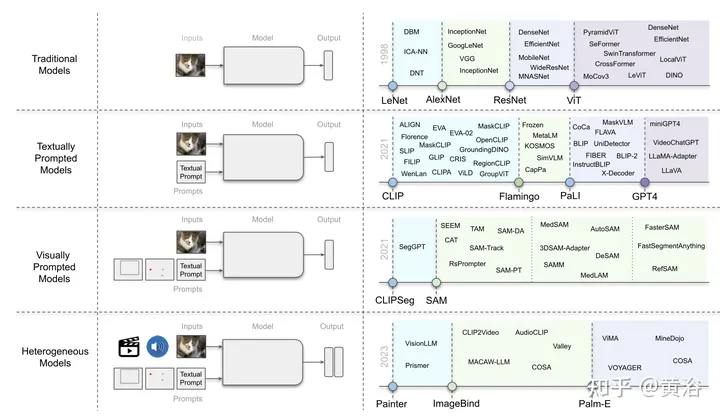
传统上,视觉语言模型主要用于需要同时理解视觉和文本模态的任务。然而,随着CLIP展示出的卓越性能,基于语言监督的模型在显著上升,并成为主流方法。在本节中,我们专注于探索依赖语言作为主要监督来源的方法。这些以文本为提示的模型可以广泛分为三种主要类型:对比、生成和混合方法。
visually prompted models #
- Foundational SAM
heterogeneous models #
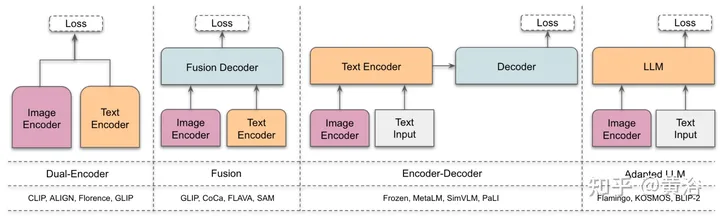
架构 [1] #
{% asset_img ’’ %}
论文[MM-LLMs] #
论文[MLLM] #
-
论文地址 A Survey on Multimodal Large Language Models A Survey on Multimodal Large Language Models 中国科学技术大学 腾讯
-
开源地址 Repo
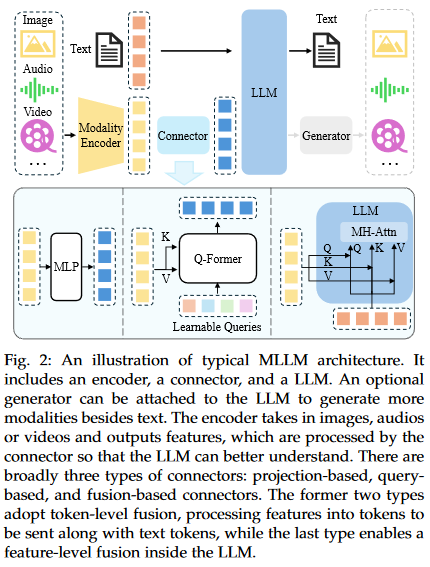
Arch [3.2] #
{% asset_img ’’ %}
类型[3.1] #
- 本文将最近具有代表性的MLLM分为4种主要类型:
- 多模态指令调整(MIT)
- 多模态上下文学习(M-ICL)
- 多模态思想链(M-CoT)
- LLM辅助视觉推理(LAVR)【类似agent】
参考 #
survey #
-
《Foundational Models Defining a New Era in Vision: A Survey and Outlook》 视觉大模型的全面解析 基础模型定义视觉的新时代:综述和展望 万字长文带你全面解读视觉大模型
-
xxx
-
《A Survey on Multimodal Large Language Models》 v1 v2版本 3.1 MLLM首篇综述 | 一文全览多模态大模型的前世、今生和未来 v1版本 3.2 多模态大语言模型全面综述:架构,训练,数据,评估,扩展,应用,挑战,机遇 v2版本