Data processing[17] #
长文本 变成 QA pair
- 规则匹配
- 利用LLM抽取
- 人工处理
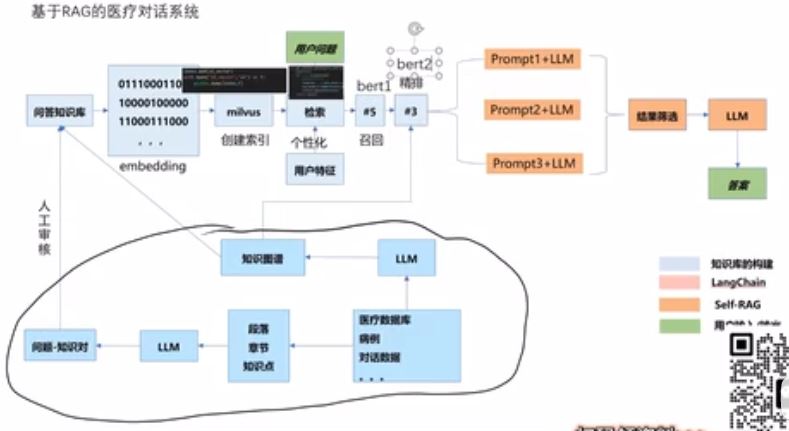
医疗问答RAG[20] #
架构 #
chuck #
段落 句子 token
数据格式 #
{“id”: xxx, “病情描述”: “xxx”, “治疗方案”: “xxx” }
改写query #
- HyDE
- RAG Fusion -> Generate Similar query 用户的查询不精准,要扩充query, 用大模型改写
召回模型 #
-
bert模型
- sbert
- 2个bert模型,共享参数,s1,s2向量化后做相似度计算
- 速度快
- 相似度 欧式距离
- 在百万语料上训练
- 语料格式
[s1][s2] 0 - 无关 [s1][s2] 1-类似
- 语料格式
- sbert
-
根据query, 召回id和value整条记录
排序模型 #
- bert模型
- 1个bert模型
- 速度慢
- 格式
- query[sep]s2 -> 经过softmax,产生2分类,0-1
- 也要训练
- 同召回模型训练方式
索引方式 #
- 树索引
- 知识图谱的索引
大模型 #
- 综合归纳的作用
参考 #
xxx #
- «大模型结合 RAG 构建客服场景自动问答系统» NVIDIA大模型日系列活动