论文 #
引言 #
大型语言模型(LLM)通过思维链提示和强化学习等技术,在推理任务中取得了显著进展。然而,这些基于文本的方法在需要精确数值计算或符号操作的任务中常常力不从心。ReTool 通过引入一个强化学习框架来解决这一限制,该框架教导 LLM 如何战略性地将代码解释器整合到其推理过程中。
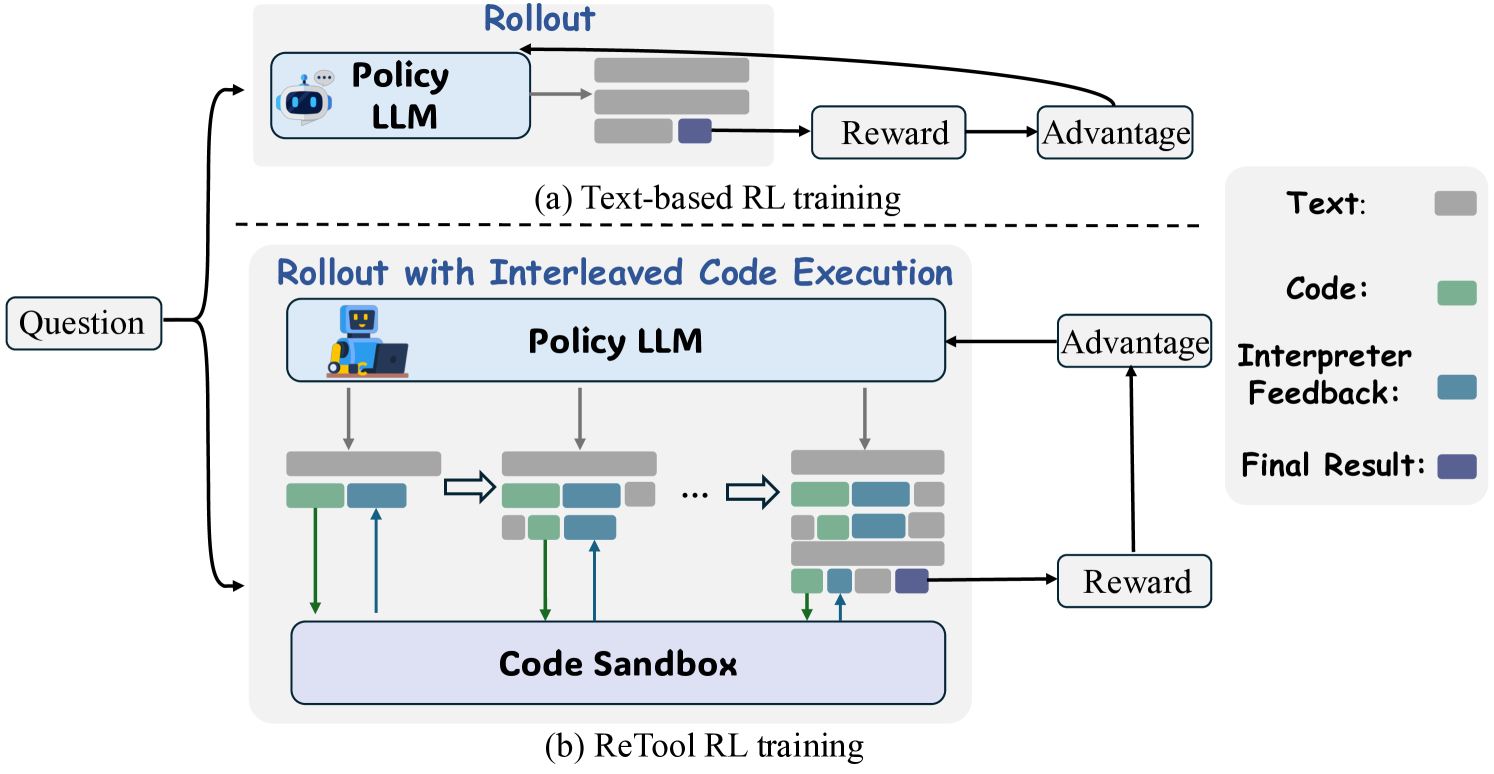 图1:传统基于文本的强化学习训练(上)与 ReTool 采用交错代码执行的方法(下)的比较。ReTool 允许在生成过程中与代码沙盒进行动态交互。
图1:传统基于文本的强化学习训练(上)与 ReTool 采用交错代码执行的方法(下)的比较。ReTool 允许在生成过程中与代码沙盒进行动态交互。
这项工作表明,LLM 不仅能学习如何使用计算工具,还能通过基于结果的反馈学习何时以及为何调用它们。这代表着与仅仅模仿预定义工具使用模式的监督微调方法相比,取得了重大进步。
方法论 #
ReTool 采用两阶段训练框架,结合监督微调和强化学习,以开发战略性工具使用能力。
冷启动监督微调 #
第一阶段通过细致的数据整理和监督训练,建立基础的工具使用能力:
数据构建过程:
- 从 Open-Thoughts 等来源初步收集高质量数学推理数据 ( \( D_{init} \) )
- 使用人类专家和 DeepSeek-R1 进行双重验证以确保质量
- 使用结构化提示将基于文本的推理自动转换为代码集成推理( \( D_{CI} \) )
- 对代码集成数据集进行额外的格式和答案验证
转换过程使用系统化的提示模板,该模板识别文本推理中的计算步骤,并将其替换为可执行的代码片段及其输出。这创建了演示何时以及如何调用代码解释器的训练数据。
带有交错代码执行的强化学习 #
核心创新在于 ReTool 的强化学习训练过程,该过程动态集成了实时代码执行:
训练算法: 采用简单基于准确性的奖励函数的近端策略优化(PPO):
\[ R(a, \hat{a}) = \begin{cases} 1 & \text{if predicted answer } \hat{a} \text{ equals ground truth } a \\ -1 & \text{otherwise} \end{cases} \]展开过程: 与传统模型生成纯文本的强化学习不同,ReTool 的展开过程包括:
- 模型生成自然语言推理
- 当代码调用被触发(通过
<code>标签)时,生成暂停 - 代码被提取并在外部沙盒环境中执行
- 执行结果(成功或错误)通过
<interpreter>标签反馈给模型 - 模型使用解释器反馈继续生成
- 过程重复直到得到最终答案或达到最大长度
技术优化:
- 解释器反馈token在损失计算中被屏蔽,以保证训练稳定性
- KV缓存重用最小化了展开过程中的内存开销
- 异步代码沙盒支持并行执行和更快的训练
结果与分析 #
ReTool 在具有挑战性的数学推理基准测试中,相较于基线方法展现出显著改进。
性能指标 #
AIME 基准测试结果:
- AIME 2024:67.0% 准确率(对比基于文本的强化学习基线为 40.0%)
- AIME 2025:49.3% 准确率(对比基于文本的强化学习基线为 36.7%)
- 训练效率:在 400 步内实现了卓越性能,而基线则需要 1000+ 步
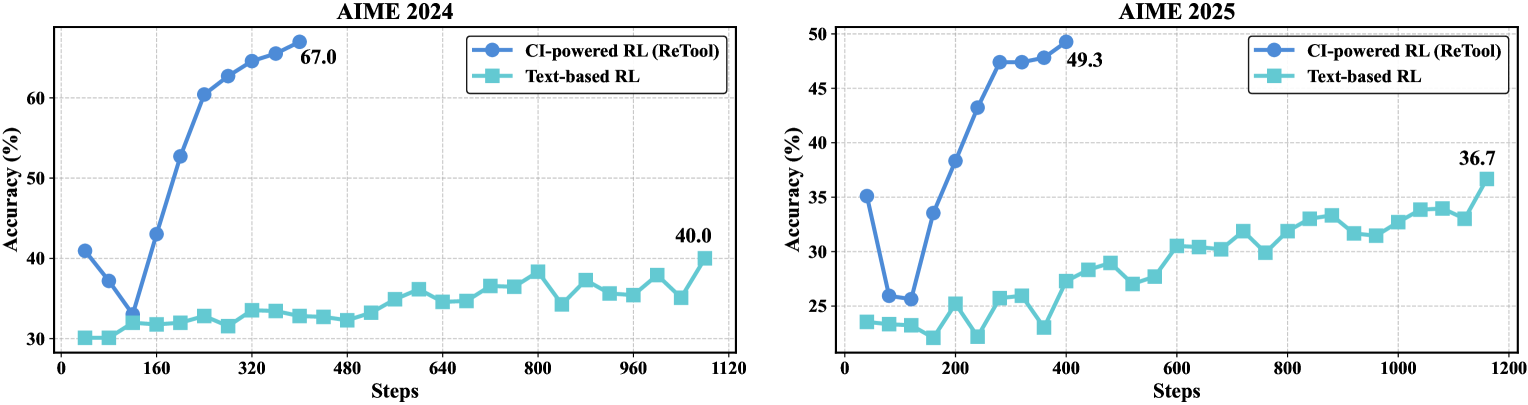 图2:训练曲线显示了 ReTool 在 AIME 基准测试中相较于基于文本的强化学习方法,具有快速的改进和卓越的最终性能。
图2:训练曲线显示了 ReTool 在 AIME 基准测试中相较于基于文本的强化学习方法,具有快速的改进和卓越的最终性能。
高级骨干模型结果: 以 DeepSeek-R1-Distill-Qwen-32B 作为基础模型,ReTool 实现了更高的性能:
- AIME 2024:72.5% 准确率
- AIME 2025:54.3% 准确率
涌现认知行为 #
分析揭示了在强化学习训练过程中出现的几个显著的涌现特性:
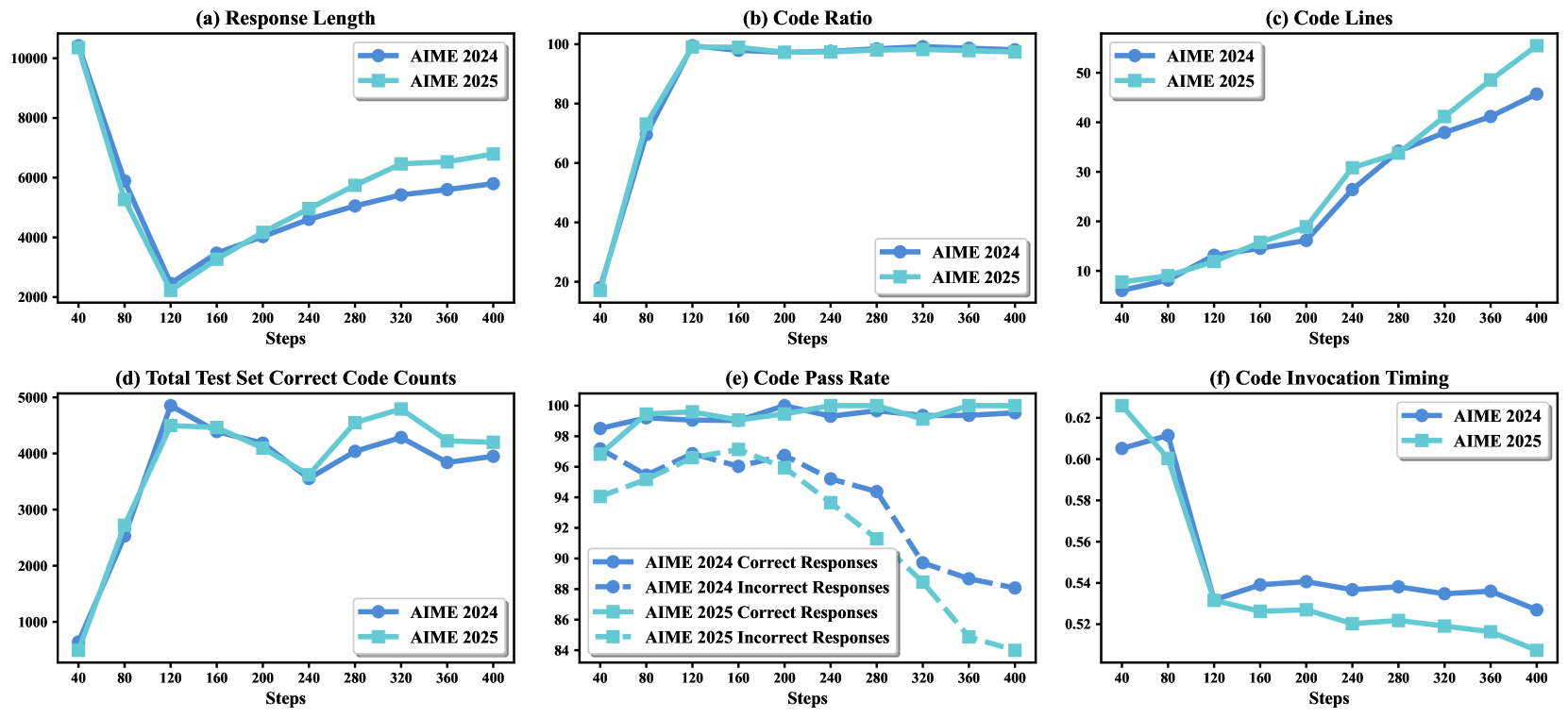 图3:ReTool 训练过程中行为变化的详细分析,展示了响应长度、代码使用模式和执行成功率的演变。
图3:ReTool 训练过程中行为变化的详细分析,展示了响应长度、代码使用模式和执行成功率的演变。
关键涌现行为:
- 令牌效率: 平均响应长度减少 40%(从 10k 减少到 6k 令牌)
- 代码采用: 代码使用率增加到近 98% 的响应
- 战略时机: 模型学会了在推理过程的早期调用代码
- 自我纠正: 自主错误检测和代码修订能力
- 多样化工具使用: 扩展了基本计算之外的功能,包括验证、优化和分析
自我纠正能力 #
最重要的发现之一是模型能够自主纠正代码执行错误:
 图4:涌现的自我纠正行为示例,模型识别并修复了其生成的代码中的 NameError。
图4:涌现的自我纠正行为示例,模型识别并修复了其生成的代码中的 NameError。
当遇到 NameError: name 'greedy' is not defined 等错误时,模型通过反思错误并生成修正后的代码,展示了元认知意识,而无需为此行为进行明确的训练。
工具使用演变 #
这项研究提供了关于代码使用模式在训练期间如何演变的见解:
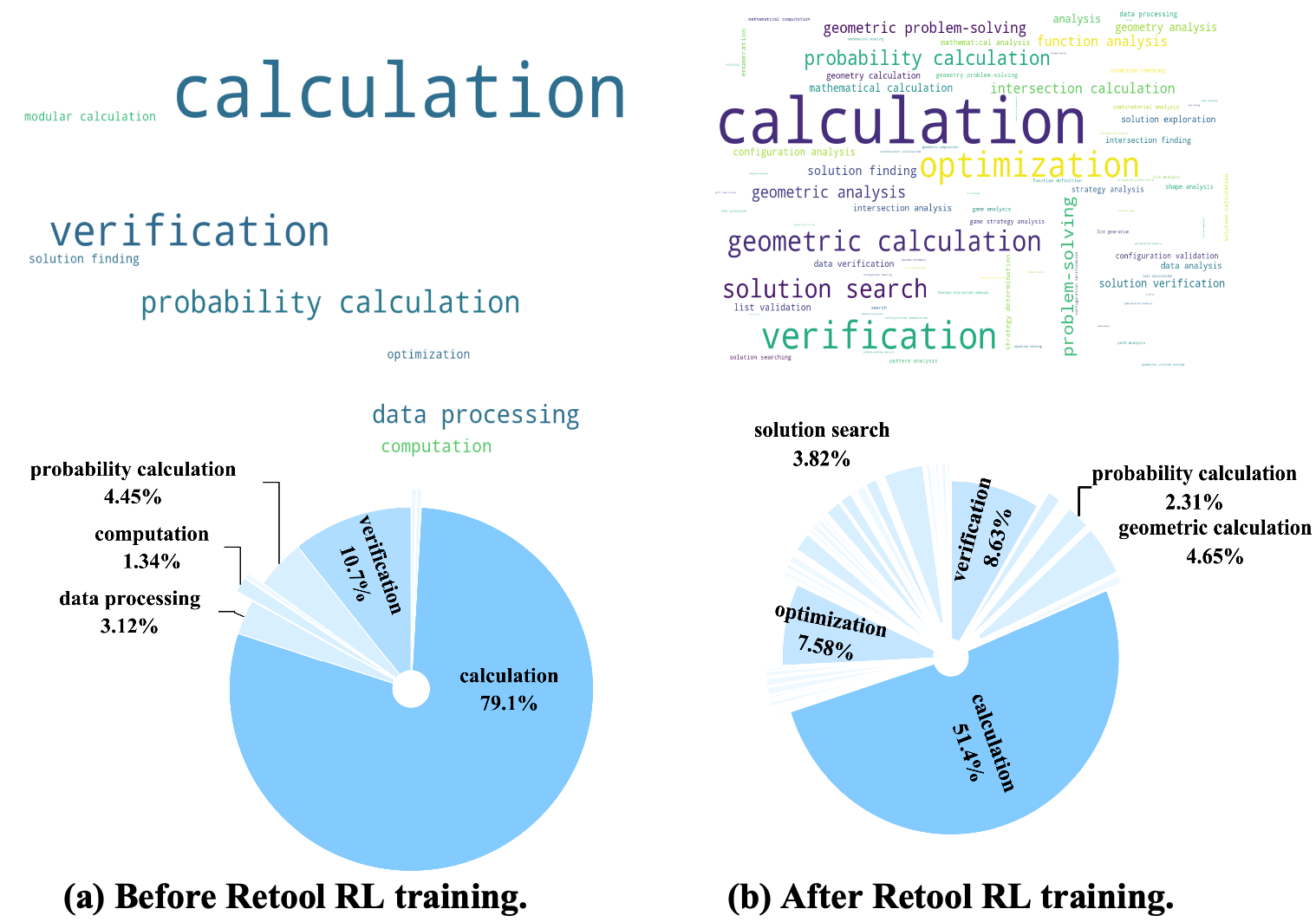 图5:词云分析显示了 ReTool 训练前后代码目的的演变,展示了工具使用策略多样性的增加。
图5:词云分析显示了 ReTool 训练前后代码目的的演变,展示了工具使用策略多样性的增加。
分析表明,虽然“计算”仍然是主要目的,但强化学习训练导致了更多样化的代码应用,包括几何分析、概率计算和解决方案验证。
比较分析 #
ReTool 的方法比传统的基于文本的推理具有明显的优势:
 图6:在复杂数学问题上,基于文本的推理(左)与代码集成推理(右)的并排比较,突出了精度和效率的提升。
图6:在复杂数学问题上,基于文本的推理(左)与代码集成推理(右)的并排比较,突出了精度和效率的提升。
比较表明,代码集成消除了容易出错的冗长手动计算,使模型能够专注于更高级别的战略推理,同时将精确计算卸载到解释器。
意义和影响 #
ReTool 代表了混合神经-符号人工智能系统的重大进步,它证明了大型语言模型可以通过强化学习而不是单纯的模仿来学习战略性工具使用。这项工作的贡献包括:
技术贡献:
- 首次成功将强化学习应用于大规模战略性代码解释器使用
- 展示了无需明确训练即可涌现的自我纠正能力
- 高效的训练框架,以更少的步骤实现了卓越的性能
更广泛的影响:
- 弥合了神经网络模式识别与符号计算之间的鸿沟
- 为跨不同领域更通用化的工具使用奠定了基础
- 通过明确的计算步骤增强了可解释性
- 展示了自主发现问题解决策略的潜力
这项研究确立了 ReTool 作为开发更强大、更通用的人工智能系统的一种引人注目的方法,这些系统能够有效地结合神经网络和符号计算范式的优势。