简介 #
Qwen 团队发布了 Qwen3,这是一个新的大型语言模型(LLM)系列,代表了开源人工智能领域的重大进步。Qwen3 涵盖了各种参数规模的密集和混合专家(MoE)架构,旨在平衡性能、效率和可访问性。
这个最新版本建立在以前的 Qwen 模型之上,在推理能力、多语言支持和推理效率方面进行了重大改进。Qwen3 的一项关键创新是在单个模型中集成思考和非思考模式,无需在不同任务的专用模型之间切换。这些模型在 Apache 2.0 许可下发布,有助于开源人工智能技术生态系统的发展,并将 Qwen3 定位为 GPT-4o、Claude 3.7 和 Gemini 2.5 等专有模型的有竞争力的替代方案。
模型架构与创新 #
Qwen3 在 Qwen2.5 的基础上进行了多项架构增强:
- 双模架构:该模型集成了思考和非思考模式,允许用户根据任务需求选择合适的模式。
- 混合专家(MoE):Qwen3 系列包括 MoE 模型,这些模型以较少的激活参数在推理期间实现高性能,从而提高计算效率。
- 核心组件:该架构包含以下高级功能:
- 分组查询注意力(GQA)
- SwiGLU 激活函数
- 旋转位置嵌入(RoPE)
- RMSNorm 和 QK-Norm
- 模型变体:Qwen3 系列包括针对不同用例量身定制的多个模型:
- Qwen3-235B-A22B:一个旗舰级的 MoE 模型,总参数为 235B,但在推理期间只有 22B 处于激活状态
- Qwen3-32B:一个旗舰级的密集模型
- 参数范围从 14B 到 0.6B 的较小模型
- 扩展上下文长度:这些模型支持高达 128K 的上下文长度,从而能够处理更长的文档和更复杂的交互。
训练方法 #
Qwen3 采用一种复杂的、多阶段的训练过程,旨在增强各种能力:
-
预训练数据:这些模型在包含 119 种语言和方言的 36 万亿个 token 的庞大数据集上进行训练,与以前版本中支持的 29 种语言相比,这是一个显着的扩展。
-
三阶段预训练过程:
- 一般知识获取
- 推理能力增强
- 长上下文适应
-
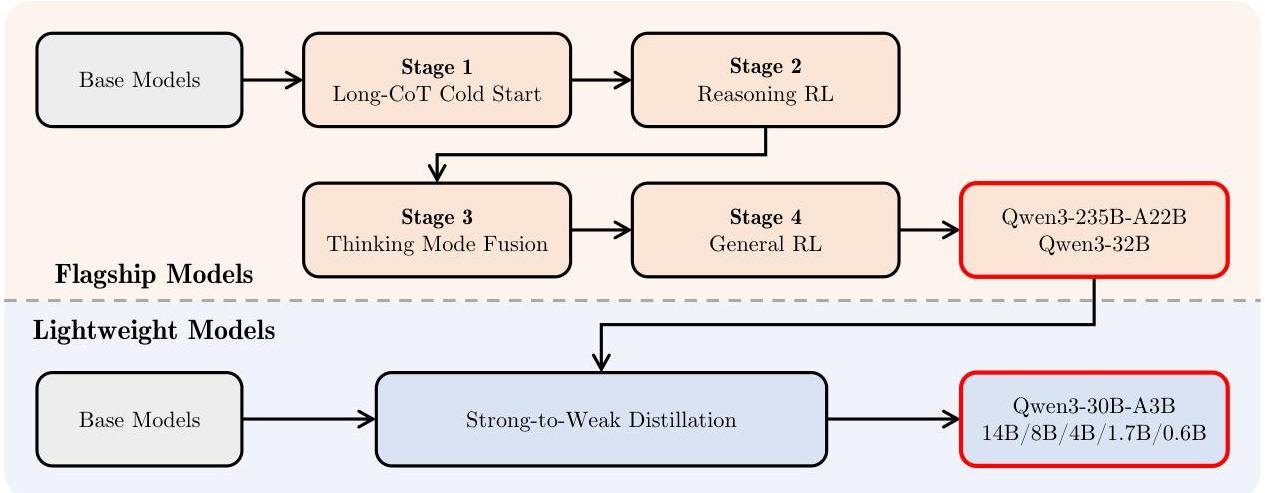
后训练对齐:一个四阶段的过程使模型与人类偏好对齐:
基础模型 → Long-CoT 冷启动 → 推理 RL → 思考模式融合 → 通用 RL -
每个阶段都针对特定的能力:
- Long-CoT 冷启动:引入思维链推理
- 推理 RL:强化准确的推理路径
- 思考模式融合:集成思考和非思考模式
- 通用 RL:增强整体模型对齐
-
数据整理:训练过程涉及多模态数据增强,包括从 PDF 中提取文本和生成合成数据,以及实例级数据混合优化。
思考模式和预算 #
Qwen3 最具创新性的功能之一是其思考模式和预算机制,这为用户提供了对模型推理深度进行细粒度控制的能力:
- 思考模式与非思考模式:
- 非思考模式:针对简单任务进行了优化,可直接提供答案,无需大量推理。
- 思考模式:进行更深入的推理,展示复杂问题的工作和中间步骤。
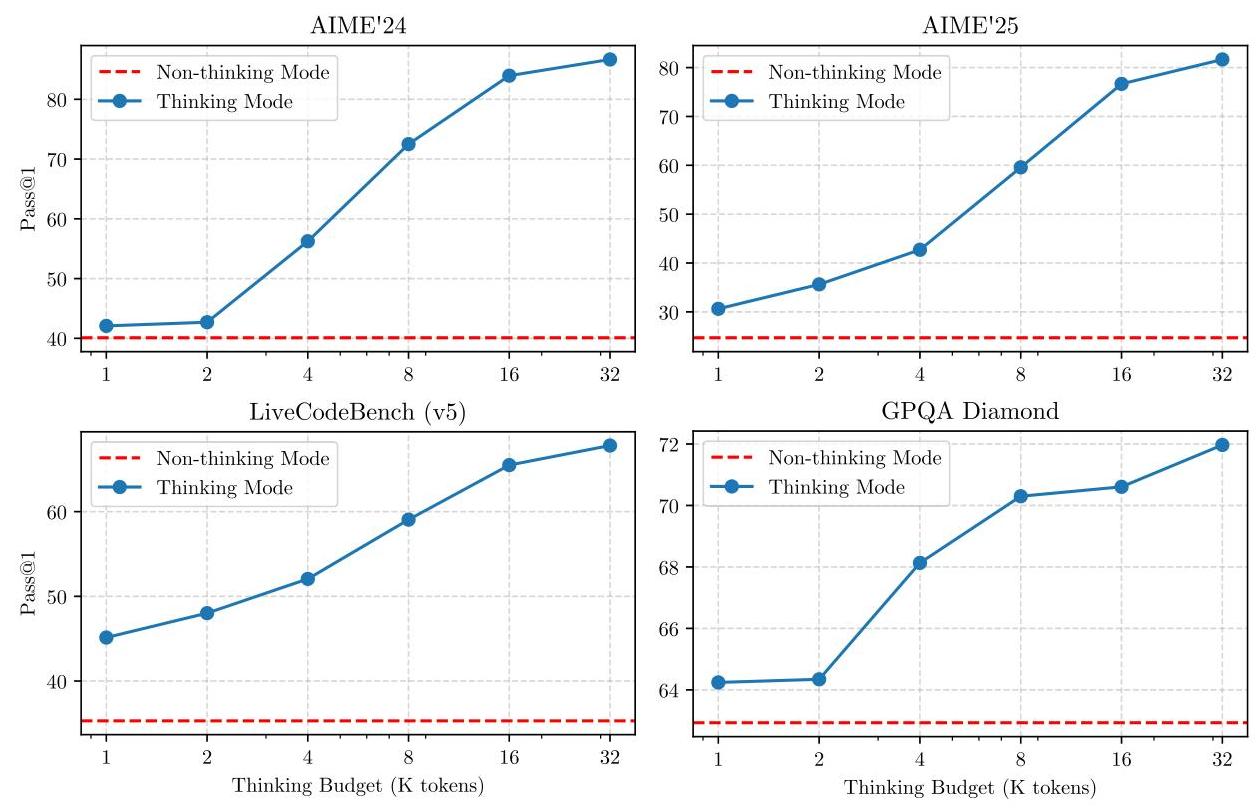
- 思考预算: 用户可以指定一个“思考预算”(以千个 tokens 为单位),以控制模型应应用的推理量。这在两种模式之间创建了一个频谱,而不是二元选择。
- 性能相关性:如上图所示,增加思考预算可以持续提高各种基准测试的性能,包括 AIME 数学推理、LiveCodeBench 编程和 GPQA Diamond 科学推理。
- 数学表达式:思考预算和模型性能之间的关系可以近似表示为:
其中 \( P(b) \) 是预算为 \(b\) 时的性能, \(b_{\text{max}}\) 是最大有效预算。
多语言能力 #
Qwen3 代表了多语言支持方面的重大进步:
- 扩展的语言覆盖范围:该模型支持 119 种语言和方言,比以前版本中的 29 种语言有了大幅增加。
- 预训练方法:多语言能力嵌入在预训练期间,并经过精心的数据管理,以确保不同语言的平衡表示。
- 性能改进:Qwen3 展示了增强的跨语言理解和生成能力,使其对全球用户更具可访问性。
- 语言分布:训练数据包括英语以外的各种语言,其中普通话和其他广泛使用的语言占了很大比例,并且改进了对低资源语言的覆盖。
强到弱的知识蒸馏 #
为了增强 Qwen3 的可访问性,该团队采用了强到弱的知识蒸馏方法:
- 知识转移:来自较大模型(Qwen3-235B-A22B 和 Qwen3-32B)的知识被提炼到较小的模型中(范围从 14B 到 0.6B 参数)。
- 蒸馏过程:该过程包括训练较小的模型来模仿较大模型的行为,同时保持双重模式能力。
- 优点:
- 减少了部署所需的计算资源
- 保持了各种任务的性能
- 保持了思考和非思考模式能力
- 实施:
# 用于强到弱的知识蒸馏的简化伪代码
def distill_knowledge(teacher_model, student_model, training_data):
for batch in training_data:
# 获取教师模型在思考和非思考模式下的输出
teacher_thinking_output = teacher_model(batch, mode="thinking")
teacher_nonthinking_output = teacher_model(batch, mode="non-thinking")
# 训练学生模型以匹配两种模式
student_thinking_loss = loss_fn(student_model(batch, mode="thinking"),
teacher_thinking_output)
student_nonthinking_loss = loss_fn(student_model(batch, mode="non-thinking"),
teacher_nonthinking_output)
# 更新学生模型的参数
total_loss = student_thinking_loss + student_nonthinking_loss
total_loss.backward()
optimizer.step()
性能和基准测试 #
Qwen3 在各种基准测试中表现出具有竞争力的性能:
- 通用任务:在衡量常识推理、阅读理解和知识检索的基准测试中表现出色。
- 数学与 STEM:数学推理能力显著提高,在 MATH、AIME 和 GPQA 等基准测试中得到验证。
- 编码:在 HumanEval 和 LiveCodeBench 等编程基准测试中表现出竞争优势,并且随着思考预算的增加,思考模式明显优于非思考模式。
- 多语言任务:在不同语言中性能得到增强,表明扩展多语言支持的有效性。
- 与其他模型的比较:Qwen3 在开源模型中取得了最先进的结果,并缩小了与更大的专有模型之间的差距。
- 效率优势:与具有相似能力的密集模型相比,MoE 模型以更少的激活参数表现出高性能。
开源贡献 #
在 Apache 2.0 许可下发布 Qwen3 代表了对开源 AI 社区的重大贡献:
- 模型可访问性:完整的模型权重和代码通过 Hugging Face、ModelScope 和 GitHub 等平台提供。
- 文档和示例:提供全面的文档和示例代码,以方便采用和实验。
- 社区参与:开源发布能够更广泛地研究、开发和部署先进的 LLM。
- AI 民主化:通过免费提供最先进的模型,Qwen3 有助于缩小大型组织与小型实体或个体研究人员之间的资源差距。
未来方向 #
Qwen 团队概述了未来研究和开发的几个方向:
- 扩展预训练:进一步增加预训练数据的大小和多样性,以增强模型能力。
- 架构改进:继续改进模型架构,以提高效率和性能。
- 扩展上下文长度:探索处理超出当前 128K 限制的更长上下文的技术。
- 增强推理:开发更复杂的推理控制和验证方法。
- 多模态能力:扩展到多模态理解和生成。
- 强化学习:增加专门用于强化学习的计算资源,以提高模型对齐和指令遵循能力。
总而言之,Qwen3 代表了开源大型语言模型的重大进步,提供了一套全面的模型,具有竞争力的性能、创新的思考控制机制、扩展的多语言支持和高效的架构设计。 在单个模型中集成思考和非思考模式,以及思考预算机制,为用户提供了前所未有的控制,可以控制应用于不同任务的推理深度,从而优化性能和效率之间的平衡。