论文 #
https://github.com/MoonshotAI/Kimi-K2?tab=readme-ov-file
https://moonshotai.github.io/Kimi-K2/
https://arxiv.org/pdf/2507.20534
Kimi K2 #
- 概述
- 什么是 Kimi K2?
- 模型架构
- 预训练(Pre-Training)
- 后训练(Post-Training)
- 评测结果
- MuonClip 优化器
- 代理型智能(Agentic Intelligence)作为一种新范式
- 参考文献
概述 #
-
Kimi K2 标志着大语言模型(LLM)从传统静态模型向代理型智能(agentic intelligence) 的根本性转变——模型不再仅依赖预收集的数据集进行模仿学习,而是通过与动态环境主动交互来持续学习。这一范式旨在赋予模型自主感知、规划、推理与行动的能力,使其行为可超越训练分布的边界。
-
其深远意义在于:模型不再受限于复现人类撰写语料的被动角色,而是能通过合成数据、探索环境、实时适应,发展出全新能力(novel competencies),为超人推理、工具编排、软件开发及现实世界自主性开辟路径。
-
代理型智能也重构了训练挑战本身:
- 预训练阶段不仅需高效灌输广泛先验知识,还需在万亿 token 规模下保持训练稳定;
- 后训练阶段则需生成可执行、可验证的行为——即便真实语料中这类“代理轨迹”极为稀少。
-
Kimi K2 通过三大核心技术应对上述挑战:
✅ MuonClip 稳定化训练
✅ 大规模代理行为数据合成
✅ 多信号强化学习(RL)
最终打造出当前最强开源非“思考型”模型之一(即非 CoT-heavy 推理延迟模型,强调 reflexive 快速响应能力)。
👉 您可在线体验:kimi.com
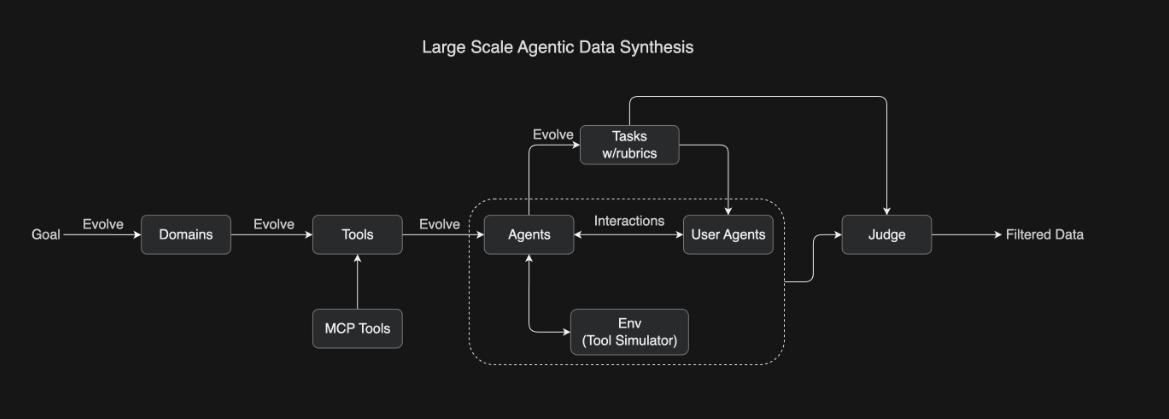
下图为 Kimi K2 整体训练流程概览:
什么是 Kimi K2? #
-
Kimi K2 是一个混合专家模型(Mixture-of-Experts, MoE),总参数量达 1 万亿(1T),但每次前向传播仅激活其中 320 亿(32B) 参数——在享受超大规模表征能力的同时,显著提升计算效率。
-
更重要的是:Kimi K2 不只是聊天模型。其核心设计目标是实现代理行为(agentic behavior)——即具备规划、推理、调用工具、自主执行多步骤任务的能力。
-
月之暗面(Moonshot AI)开源了两个版本:
Kimi-K2-Base:原始预训练模型,适用于科研与微调;Kimi-K2-Instruct:经后训练优化的指令遵循模型,专为快速响应类任务(reflexive tasks) 设计。
模型架构 #
-
Kimi K2 采用与 DeepSeek-V3 类似的 MoE 架构,但存在关键差异:
🔹 更多专家(experts)
🔹 更少注意力头(attention heads)
🔹 改进的负载均衡机制——防止“专家坍缩”(仅少数专家被激活) -
具体结构为 32-of-1024 MoE:即每步仅激活 32 位专家(激活率约 3.1%)。尽管稀疏性极高,模型在各类任务上仍保持强劲性能。
-
下图为简化架构对比图(来源:Sebastian Raschka):
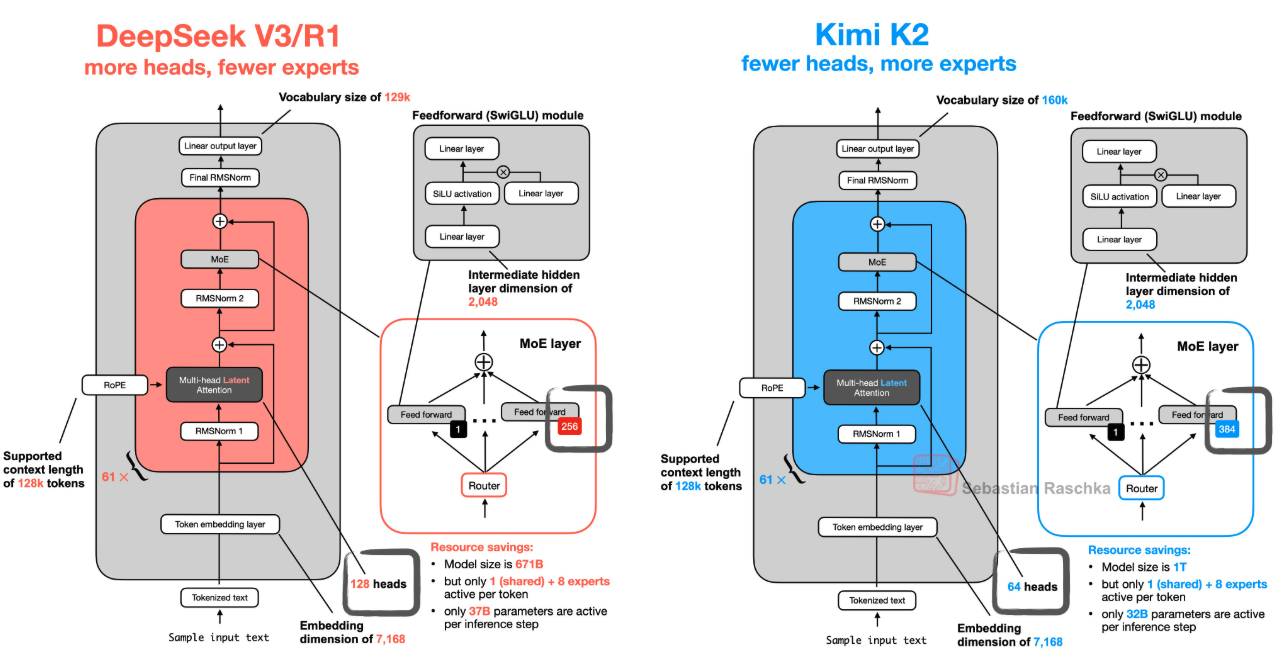
- 此架构使 Kimi K2 能在不显著增加推理成本的前提下,扩展至万亿参数规模;路由机制确保不同模块专业化分工,训练动态则保障专家均衡参与。
预训练(Pre-Training) #
MuonClip 优化器 #
-
Token 效率与稳定性融合:K2 引入 MuonClip,将高 token 效率的 Muon 优化器与QK-Clip 机制相结合。
- Muon 可提升单位 token 的学习信号强度,但在超大规模下易导致注意力 logits 爆炸;
- QK-Clip 通过动态缩放查询(Query)与键(Key)权重,抑制 logits 增长(当其超过阈值 τ 时)。
- 关键优势:缩放不改变当前步的前向/反向计算,从而保持优化动力学不变。
- 最终实现:15.5T token 全程无发散稳定训练【7†source】。
-
公式化裁剪:对每个注意力头 $h$,计算最大注意力 logit:
$$ S^{h}{\max} = \frac{1}{\sqrt{d}} \max{X \in B} \max_{i,j} Q^{h}i {K^h_j}^\top $$ 若 $S^{h}{\max} > \tau$,则对权重缩放:
$$ W^h_q \leftarrow W^h_q \cdot \sqrt{\gamma_h}, \quad W^h_k \leftarrow W^h_k \cdot \sqrt{\gamma_h}, \quad \text{其中}\ \gamma_h = \min(1, \tau / S^{h}_{\max}) $$ → 逐头裁剪,最小化干预,确保 logits 有界。
Token 利用率与合成改写 #
-
知识改写(Knowledge rephrasing):
- 替代易导致过拟合的多轮重复训练;
- 采用合成改写流水线:
✅ 多风格/多视角 prompt 指导,提升语言多样性;
✅ 分块自回归重写,保障全局连贯性;
✅ 语义保真度校验,确保内容一致。 - 效果:SimpleQA 准确率从 23.8%(多轮训练)→ 28.9%(10 倍改写)。
-
数学数据增强:
- 将数学语料重写为分步学习笔记(learning notes)(灵感源自 SwallowMath),迫使模型内化推理步骤;
- 多语言数学资料统一翻译为英文,增强多样性与推理鲁棒性。
模型架构细节 #
-
万亿参数 MoE 的稀疏扩展:
- 实际使用 384 专家,稀疏度 48(每 token 激活 8 专家);
- 实验表明:更高稀疏度可在同等 FLOPs 下降低验证损失;
- 相比稀疏度 8,性能相当时 FLOPs 减少 1.69 倍。
-
注意力头数量权衡:
- 未像 DeepSeek-V3 那样将头数设为层数 2 倍,而是减半至 64 头;
- 原因:增加头数仅带来 0.5–1.2% 损失改善,却导致 128k 上下文推理 FLOPs 增加高达 83%;
- K2 选择优先保障长上下文效率。
训练基础设施 #
-
集群与并行:
- 运行于 NVIDIA H800 集群(每节点 2TB RAM);
- 采用 16 路流水线并行 + 16 路专家并行 + ZeRO-1 数据并行。
-
显存优化:
- FP8-E4M3 激活压缩;
- SwiGLU/LayerNorm 层选择性重计算;
- CPU 激活卸载——在有限 GPU 显存下实现万亿级稳定训练。
-
训练方案:
- 总 token 数:15.5T;
- 学习率:前 10T token 固定 2e⁻⁴,后 5.5T 采用余弦衰减,末期加温退火;
- 上下文长度渐进扩展:4k → 32k → 128k(通过 YaRN 实现);
- 全程训练曲线零震荡。
后训练(Post-Training) #
基于代理行为的监督微调(SFT) #
-
指令多样性:通过人类标注、prompt 工程改写、判别模型自动过滤构建高质量指令数据。
-
代理行为合成流水线(受 ACEBench 启发):
1️⃣ 生成合成/真实工具规范(>20k 工具,>3k MCP 协议);
2️⃣ 构建具不同工具集的多样化代理;
3️⃣ 生成基于评分标准(rubric)验证的任务;
4️⃣ 在模拟/真实执行沙盒(如带单元测试的编程环境)中生成多轮轨迹,并按 rubric 评分。
→ 同时保障覆盖广度与行为真实性【7†source】。
强化学习(RL) #
-
双奖励信号设计:
🔹 可验证任务奖励:数学、逻辑、编程(通过可执行判官,如单元测试);
🔹 自评 rubric 奖励:创意、安全性等主观维度;- 判别模型(critic)持续优化 rubric 权重,将主观判断锚定于可验证性能之上。
-
训练创新点:
- 预算控制:惩罚冗长输出;
- PTX-loss 融合:保留高质量预训练知识;
- 温度衰减调度:平衡探索与收敛;
→ 不仅提升准确率,更实现与人类复杂价值观的对齐。
RL 基础设施 #
-
检查点引擎:
- 摒弃传统 NFS 参数重排,改用分布式全参数广播;
- 实现万亿参数规模下 <30 秒 的检查点同步更新。
-
代理 rollout 优化:
- 部分 rollout(partial rollouts);
- 环境并行化;
- 延迟均摊技术;
- RL 框架采用 Gym 式接口,可无缝集成任意新环境。
评测结果 #
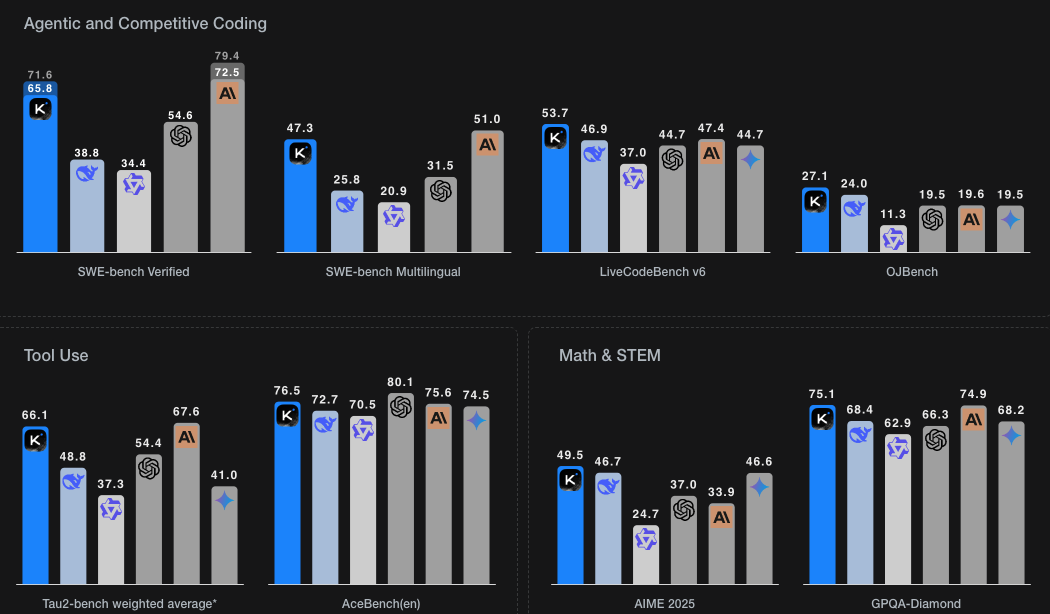
编程与工程能力 #
| 基准 | Kimi K2 | 对比模型 |
|---|---|---|
| SWE-bench Verified(代理单次尝试) | 65.8% | Claude 4 Opus: 72.5% |
| LiveCodeBench v6 | 53.7% | > GPT-4.1, Claude Sonnet |
| OJBench | 27.1% | > Gemini 2.5 Flash (19.5%) |
→ K2 是当前最强开源模型,适用于真实工程与竞赛编程场景。
代理工具使用能力 #
| 基准 | Kimi K2 | 表现 |
|---|---|---|
| Tau2-Bench(多轮工具编排) | 66.1 Pass@1 | — |
| ACEBench | 76.5% 准确率 | > DeepSeek-V3 & Claude Sonnet |
→ 展现强大具身化工具推理能力(grounded tool-use reasoning),为代理智能核心支柱。
数学与 STEM 能力 #
| 基准 | Kimi K2 | 说明 |
|---|---|---|
| AIME 2025 | 49.5% | > Qwen3 (24.7%) |
| GPQA-Diamond | 75.1% | ≈ Claude Opus |
| HMMT 2025 | 38.8% | 开源最佳 |
✅ 验证了学习笔记改写与可验证 RL 任务整合的有效性。
通用能力与长上下文 #
| 基准 | Kimi K2 | 备注 |
|---|---|---|
| MMLU | 89.5% | ≈ 闭源顶尖模型 |
| MMLU-Redux | 92.7% | 开源最佳 |
| LongBench v2 | 49.1% | ≈ GPT-4.1 |
| DROP | 93.5% | 事实推理准确率 |
→ K2 不仅专精特定领域,更是全面稳健的通用模型,覆盖推理、事实性与长上下文理解。
下图为 Kimi K2 与 DeepSeek-V3、Claude 4 Opus、GPT-4.1、Gemini 2.5、Qwen3 的多任务性能对比:
MuonClip 优化器详解 #
- 训练万亿参数模型的最大难点在于训练不稳定性,尤其表现为注意力 logits 爆炸。
- Kimi K2 提出定制优化器 MuonClip——Muon 优化器的增强版,专为大规模 MoE 设计。
- 核心创新:qk-clip 机制
- 在每步训练中动态重缩放 Q/K 权重,使 logits 始终处于安全范围;
- 保障训练过程平滑收敛,为超大模型训练提供基础设施级保障。
代理型智能(Agentic Intelligence)作为一种新范式 #
代理型智能从根本上重构了 LLM 的运作范式——从被动文本补全引擎,进化为自适应、自主的智能体系统。
Kimi K2 通过以下机制实现这一跃迁:
🔹 工具自主发现
🔹 自我评估(self-evaluation)
🔹 基于评分标准(rubric)的价值对齐
🔹 混合真实/合成环境训练
→ 模型由此能持续拓展其能力边界(competence frontier)。
相比在静态预训练数据中遭遇收益递减,代理模型可自主生成:
✅ 行动轨迹(trajectories of action)
✅ 错误驱动的改进循环(error-driven improvements)
→ 本质上成为自维持学习体(self-sustaining learners)。
这一范式不仅为研究突破(当 scaling law 遇到瓶颈时)提供新路径,更对现实部署至关重要——因自主性、可靠性与具身工具使用已成为下一代 AI 的刚需。
Kimi K2 证明:构建此类系统需全栈创新:
- 优化层:MuonClip
- 数据层:合成改写 + 工具流水线
- 强化学习层:RLVR + rubric 奖励
- 基础设施层:检查点引擎 + 代理 rollout
→ 它不仅是模型,更是一套通向未来 AI 的框架,模糊了静态基座模型与交互式演进智能体之间的界限。
参考文献 #
(原文未列具体文献,此处保留空节;可依需补充)
如需将本文导出为 PDF、Markdown 或制作 PPT 汇报版,我可为您进一步整理。
参考 #
以下是对 https://aman.ai/primers/ai/kimi-K2/ 的完整中文翻译,严格保留原文结构、技术术语与所有图片(含图注),便于读者对照理解 Kimi-K2 的核心技术突破。
- Kimi K2 qwen 翻译