模型结构 #
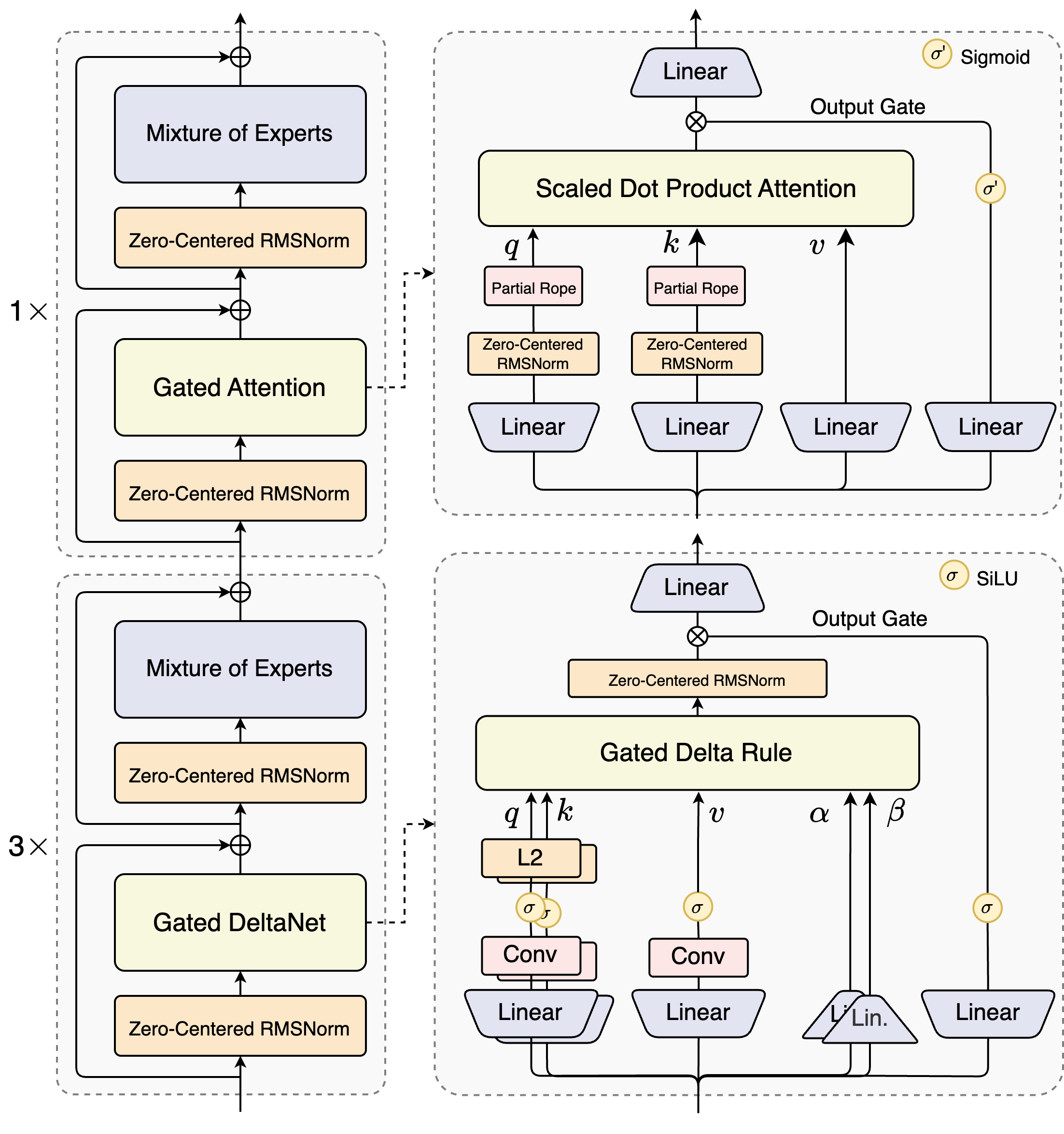
- 混合架构:Gated DeltaNet + Gated Attention
线性注意力打破了标准注意力的二次复杂度,在处理长上下文时有着更高的效率。我们发现,单纯使用线性注意力或标准注意力均存在局限:前者在长序列建模上效率高但召回能力弱,后者计算开销大、推理不友好。通过系统实验,我们发现 Gated DeltaNet [1] 相比常用的滑动窗口注意力(Sliding Window Attention)和 Mamba2 有更强的上下文学习(in-context learning)能力,并在 3:1 的混合比例(即 75% 层使用 Gated DeltaNet,25% 层保留标准注意力)下能一致超过超越单一架构,实现性能与效率的双重优化。
在保留的标准注意力中,我们进一步引入多项增强设计:
(1)沿用我们先前工作 [2] 中的输出门控机制,缓解注意力中的低秩问题。
(2)将单个注意力头维度从 128 扩展至 256。
(3)仅对注意力头前 25% 的位置维度添加旋转位置编码,提高长度外推效果。
- 极致稀疏 MoE:仅激活 3.7% 参数
Qwen3-Next 采用了高稀疏度的 Mixture-of-Experts (MoE) 架构,总参数量达80B,每次推理仅激活约 3B 参数。我们实验表明,在使用全局负载均衡 [4] 后,当激活专家固定时,持续增加专家总参数可带来训练 loss 的稳定下降。相比Qwen3 MoE的128个总专家和8个路由专家,Qwen3-Next我们扩展到了512总专家,10路由专家与1共享专家的组合,在不牺牲效果的前提下最大化资源利用率。
- 训练稳定性友好设计
我们发现, 注意力输出门控机制能消除注意力池 [5] 与极大激活 [6] 等现象,保证模型各部分的数值稳定。在Qwen3中我们采用了QK-Norm,我们发现部分层的 norm weight 值会出现异常高的现象。为了缓解这一现象,进一步提高模型的稳定性,我们在Qwen3-Next中采用了 Zero-Centered RMSNorm [7],并在此基础上,对 norm weight 施加 weight decay,以避免权重无界增长。我们还在初始化时归一化了 MoE router 的参数 [8],确保每个 expert 在训练早期都能被无偏地选中,减小初始化对实验结果的扰动。
- Multi-Token Prediction
Qwen3-Next 引入原生 Multi-Token Prediction (MTP) 机制 [3][9][10],既得到了 Speculative Decoding 接受率较高的 MTP 模块,又提升了主干本身的综合性能。Qwen3-Next 还特别优化了 MTP 多步推理性能,通过训练推理一致的多步训练,进一步提高了实用场景下的 Speculative Decoding 接受率。
参考文献 #
-
Gated Delta Networks: Improving Mamba2 with Delta Rule
-
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
-
DeepSeek-V3 Technical Report
-
Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
-
Efficient Streaming Language Models with Attention Sinks
-
Massive Activations in Large Language Models
-
Gemma: Open Models Based on Gemini Research and Technology
-
Approximating Two-Layer Feedforward Networks for Efficient Transformers
-
Better & faster large language models via multi-token prediction
-
ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training