📌 0. 背景 #
- Kimi-K1.5 与 DeepSeek-R1 几乎同步发布(2025-01-20),二者推理能力均达到 OpenAI o1 水平。
- Kimi-K1.5 是多模态模型;DeepSeek-R1 仅文本。
- 相比 DeepSeek-R1,Kimi-K1.5 技术报告披露了更多可落地的算法细节,尤其在 RL 数据构建、评估、采样方面极具参考价值。
🧱 1. 整体架构 #
采用标准三阶段流程:
Pre-training → SFT → Reinforcement Learning(RL)
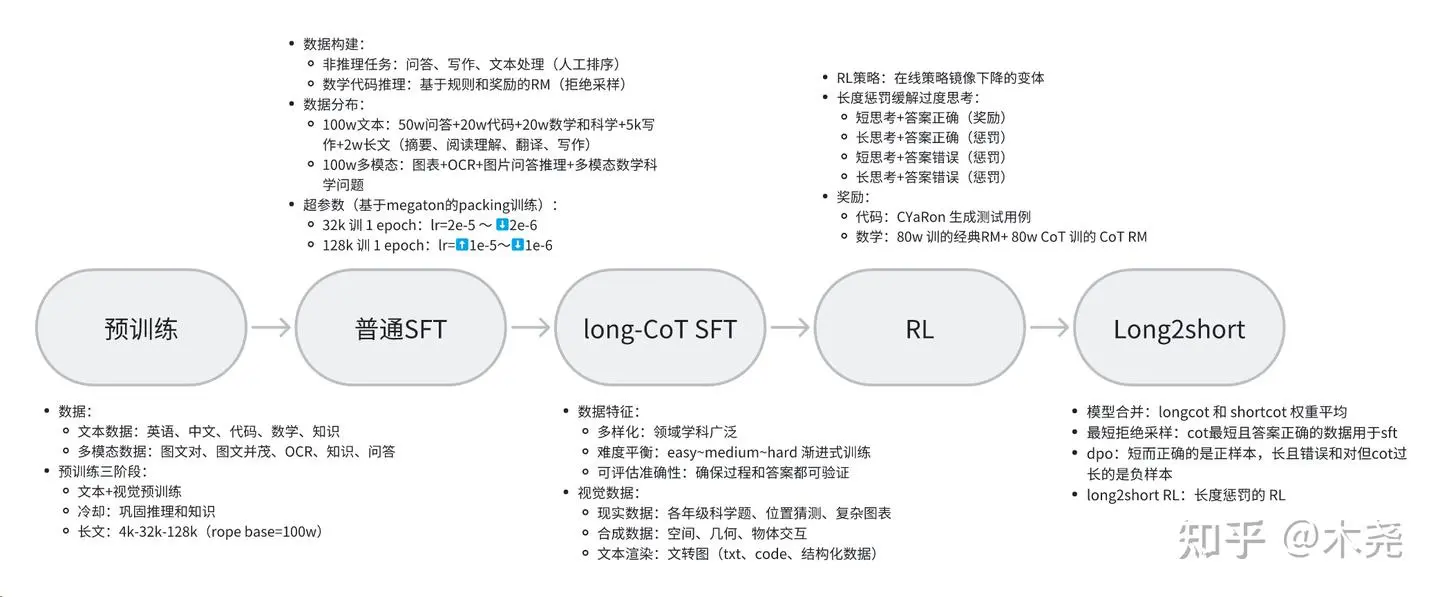
(图源:木尧|知乎)
🔤 2. 预训练(Pre-training) #
分三阶段:
阶段一:视觉-语言预训练 #
- 先训纯语言模型(LLM),再逐步加入多模态数据;
- Vision tower 独立训练,初期不更新 LLM 参数;
- 后期图文交织数据从 0% → 30%,逐步放开 LLM 更新。
阶段二:冷却(Cooling)阶段 #
- 用精选 + 合成数据(QA 对)巩固推理/知识能力;
- 合成方式:用专有模型生成 → 拒绝采样保质量。
阶段三:长上下文激活 #
- 目标:支持 131,072 token 上下文;
- 关键技术:
- 过采样 long-context 数据:40% 全注意力 + 60% partial attention;
- 渐进训练:4k → 32k → 128k;
- RoPE base 频率设为 1,000,000(更大上下文需更高频率)。

→ 得到基础模型 kimi-k1.5-base。
✍️ 3. SFT 训练 #
3.1 常规 SFT #
- 数据构建:
- 非推理任务:人工种子集 → 模型生成多回复 → 人工排序+优化;
- 推理任务(数学/代码):规则+奖励模型验证 + 拒绝采样(更高效准确)。
- 数据分布(~1M):
类型 数量 一般问答 500k 编码 200k 数学/科学 200k 创意写作 5k 长上下文任务 20k 图文任务(图表/OCR/视觉推理等) 1M - 训练细节:
- Epoch 1:seq_len=32k, lr 2e-5 → 2e-6
- Epoch 2:seq_len=128k, lr 1e-5 → 1e-6
- packing 多样本训练(提升 GPU 利用率)
🔍 3.2 Long-CoT SFT(重点①) #
- 目标:让模型学会人类式深度思考:
- 规划 → 评估 → 反思 → 探索
- 数据构造:对高质量问题,用 Prompt Engineering 生成含完整思考链的长答案;
- 本质仍是 SFT,差异仅在 answer 长度与结构。
🎯 4. 强化学习(RL)——核心亮点 #
4.1 RL 数据集构建原则(三大关键) #
| 维度 | 具体做法 |
|---|---|
| 多样性 | 多领域数据 + 公司自建标签系统(核心资产未公开) |
| 难度平衡 | 高温采样 10 次 → 计算通过率定难度;动态更新(每次用最新 checkpoint);课程学习:由易→难 |
| 可精确评估 | 移除易猜题型(多选/判断/证明题);移除易 hack prompt:不走 CoT 也能高概率答对 → 剔除 |
✅ 核心原则:“答案必须可精确评估”——RL 的“宪法”。
4.2 问题定义 #
将推理建模为搜索空间优化问题:
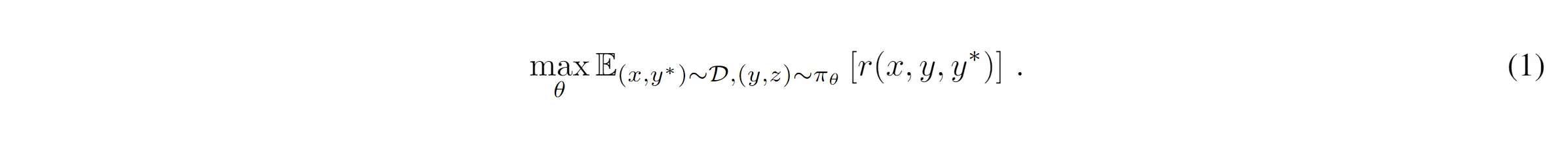
- 固定答案题:规则判断 → reward ∈ {0, 1}
- 开放问答:用奖励模型打分
4.3 策略优化 #
- 无 Value Model:与 DeepSeek-R1 的 GRPO 一致 → 保留错误路径梯度,对提升推理能力有帮助;
- 长度惩罚:防过度思考,奖励随推理长度衰减:
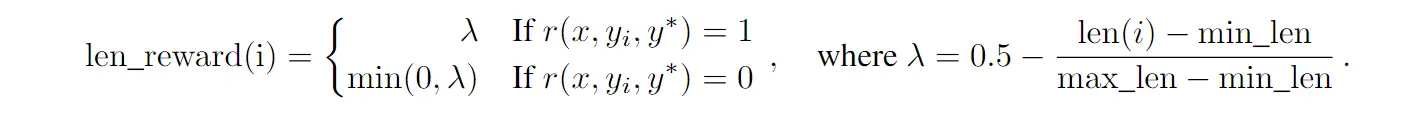
4.4 采样策略 #
- 课程采样:按难度递进;
- 优先采样:按
1 − 成功率比例采样 → 专攻短板问题。
🔥 4.5 Long2Short(重点②) #
实现 长链推理 → 短链推理 的高效迁移:
| 方法 | 说明 |
|---|---|
| 权重融合 | Long/Short checkpoint 直接加权平均(无需训练,可直接工程复用) |
| 最短拒绝采样 | 生成多条 → 选最短且正确者 |
| 长短 DPO | 构建 pair:短且正确(+) vs 长/错误(−) |
| 长度惩罚 RL | RL 阶段显式抑制冗长输出 |
4.6 其他亮点细节 #
4.6.1 代码 RL:自动生成测试用例 #
- 用 CYaRon + Kimi-k1.5 生成 → 用 10 个正确提交验证 → 通过率 ≥70% 为有效;
- 1000 题中 → 614 无特殊评测 → 323 题最终入训。
4.6.2 数学 RL:双奖励模型 #
| 类型 | 优势 |
|---|---|
| Classic RM | 输入:问题+标准答案+模型作答 → 输出标量 |
| Chain-of-Thought RM | 训练时看 CoT,效果更好(用 800k CoT+label 数据训练) |
4.6.3 视觉 RL 数据三类 #
| 类别 | 作用 |
|---|---|
| 真实世界数据 | 科学题、地点猜测、图表分析 → 提升现实推理 |
| 合成视觉数据 | 程序生成图像 → 训练空间/几何推理 |
| 文本渲染数据 | 文档→图像(截图/照片)→ 提升文字密集图理解,保证跨模态一致性 |
4.6.4 RL 框架优化 #
- 训练/推理分离框架;
- Rollout 采样优化 → 提升数据利用率:
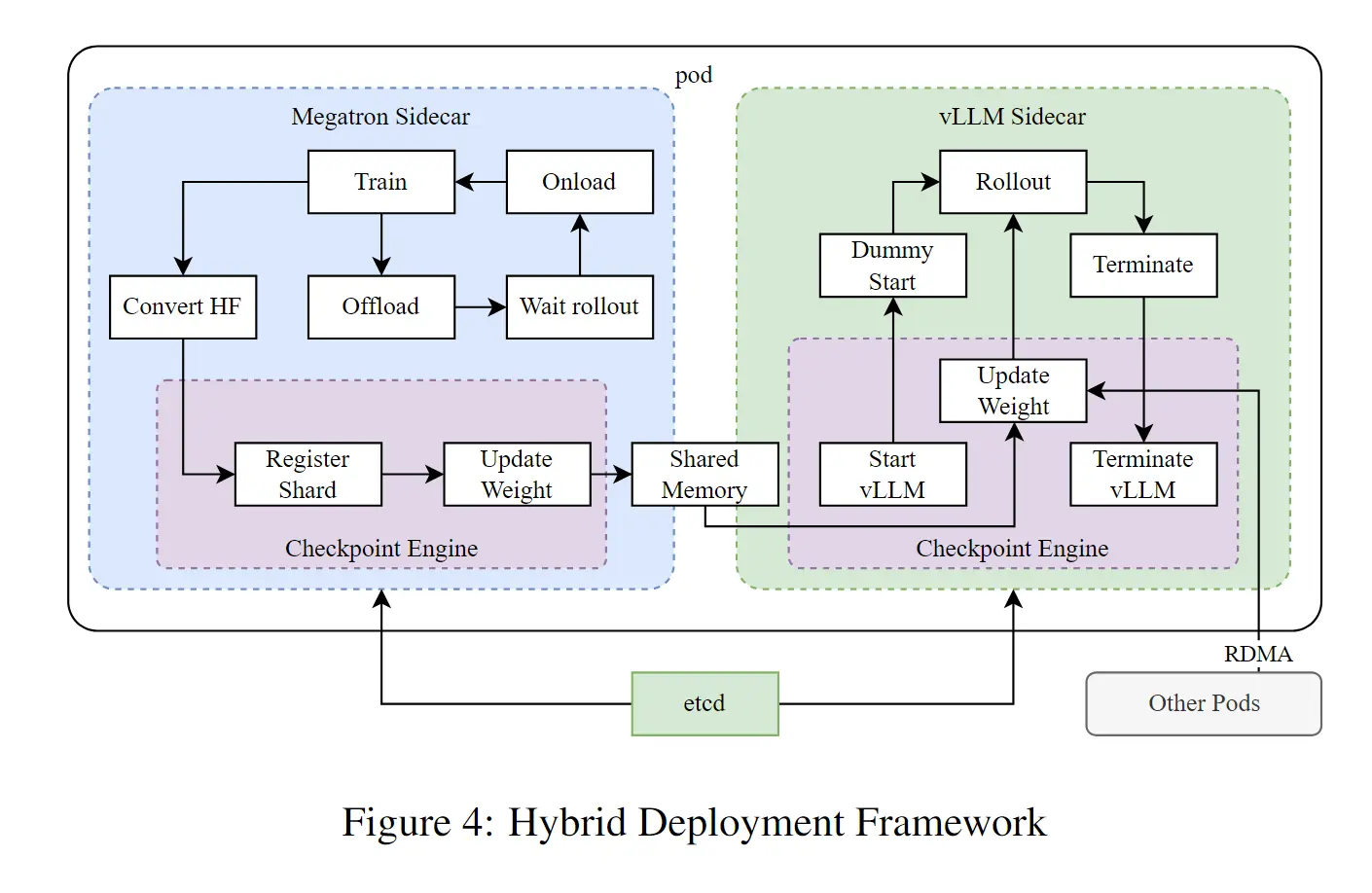
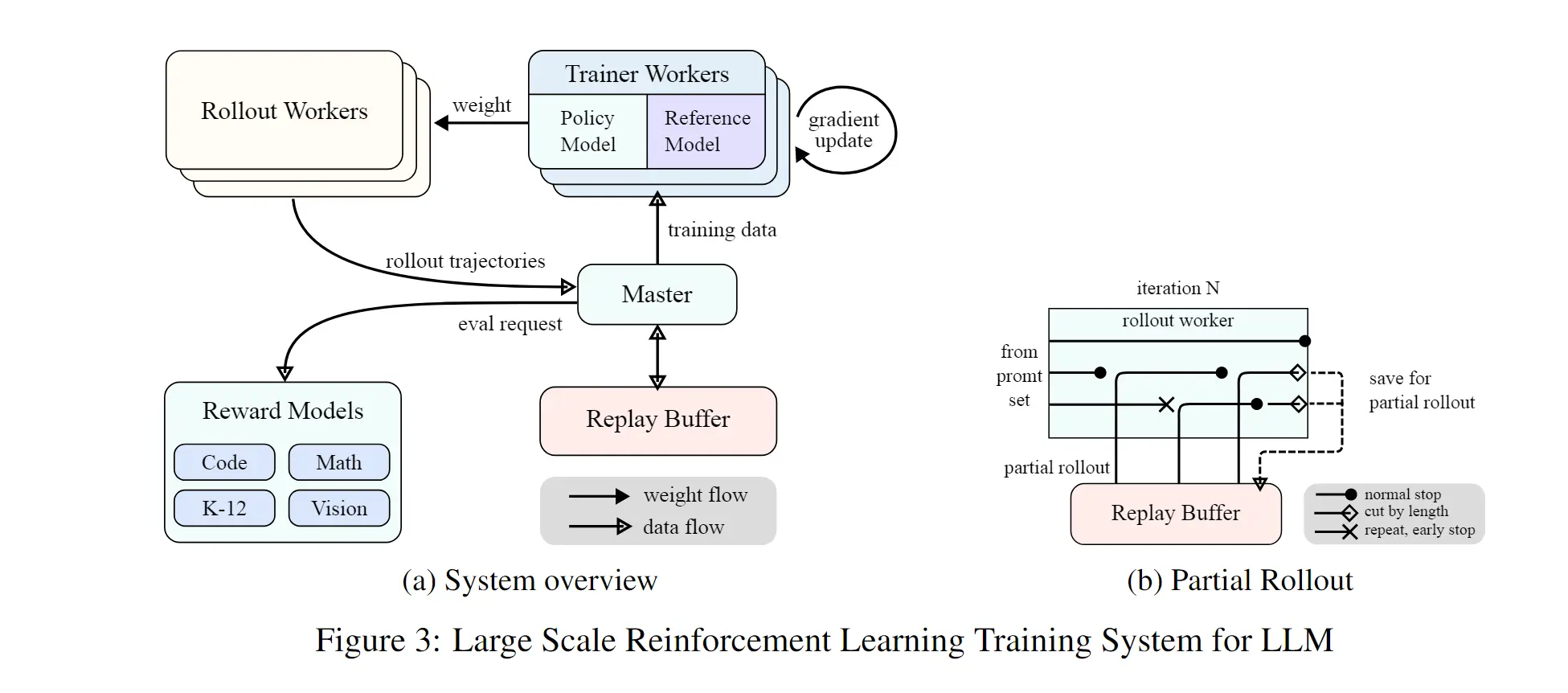
📊 5. 实验结论 #
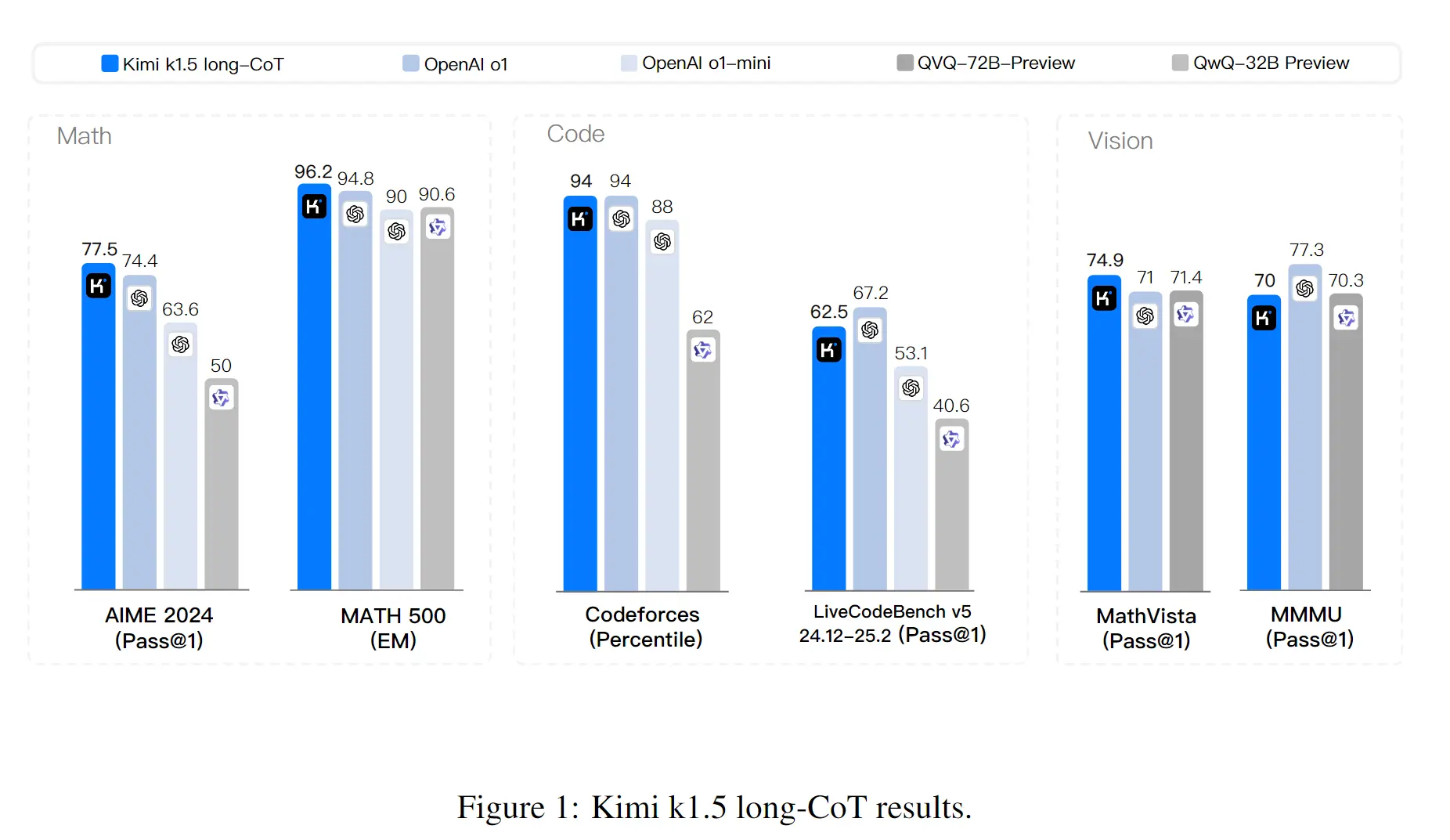
5.1 主要结果 #
- 多项 benchmark 达 o1 水平,首个追平 o1 的多模态模型:
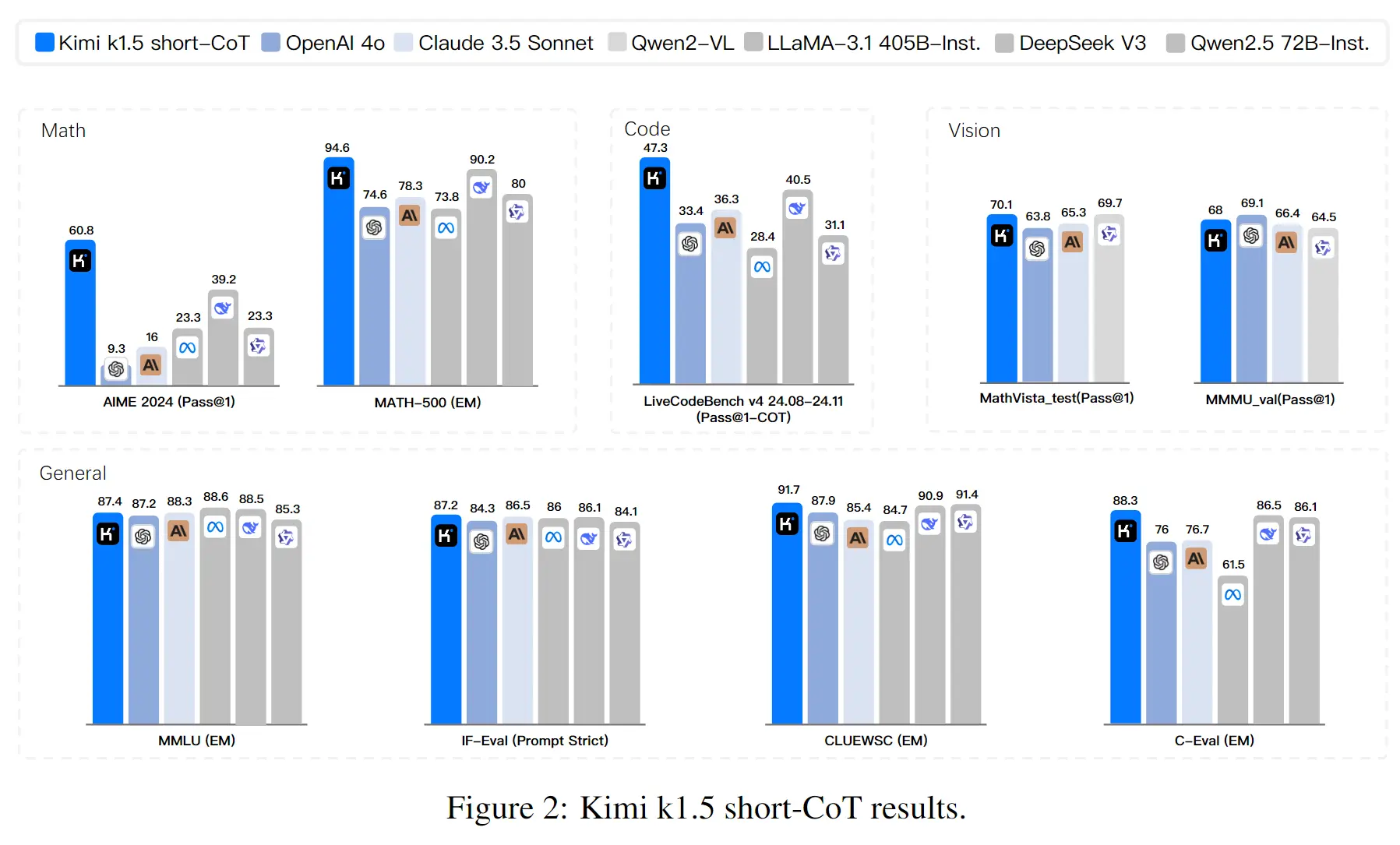
- Long2Short 后,Short 模型性能几乎无损:
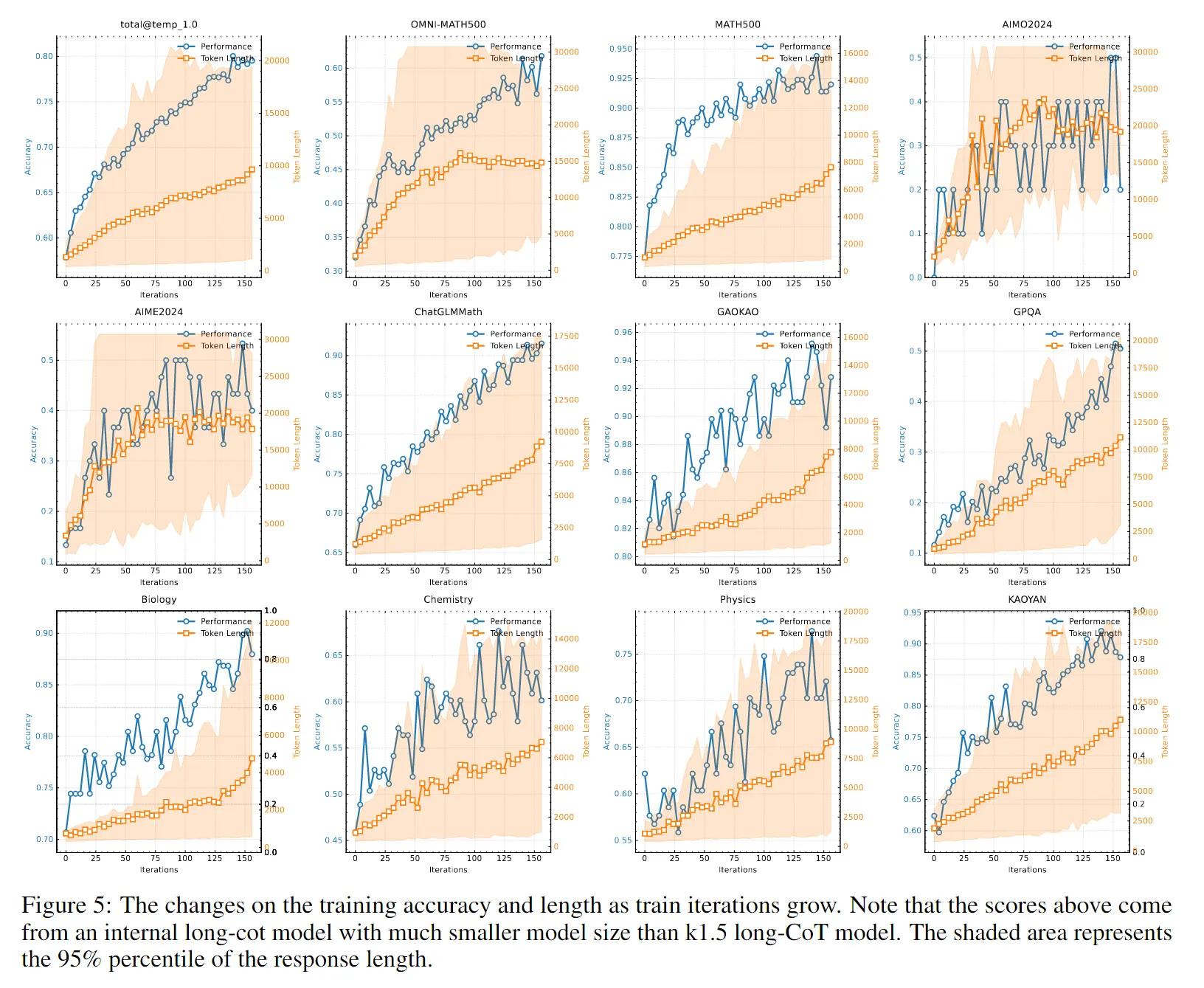
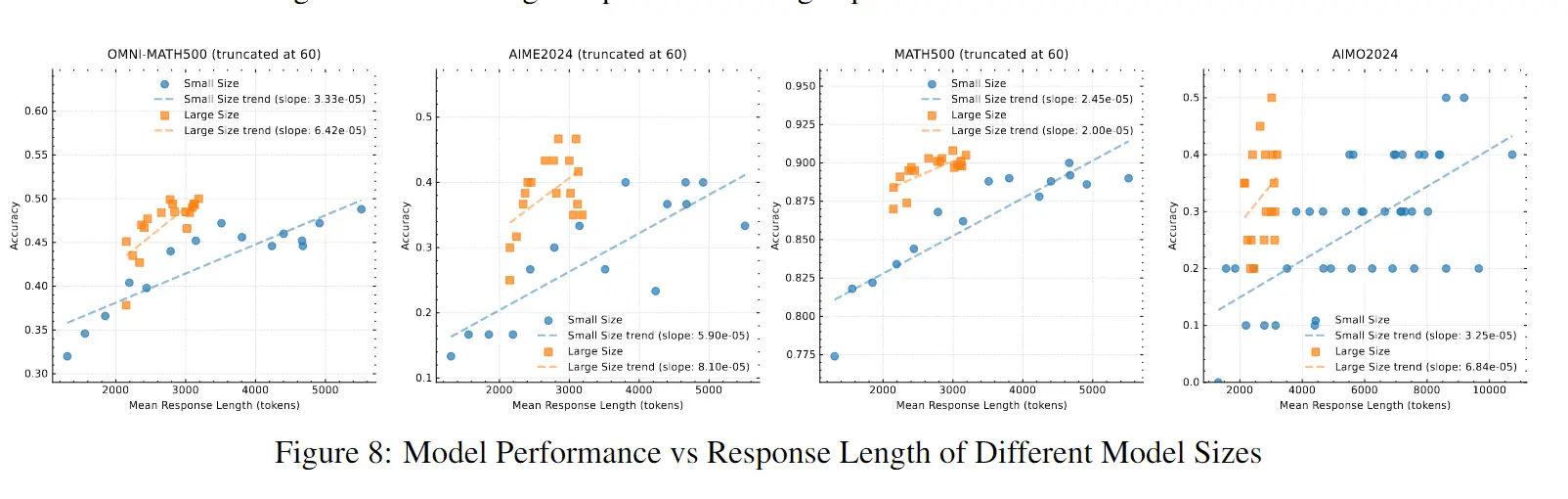
5.2 自我进化:CoT 长度 ↔ 能力正相关 #
- 模型自发生成更长 CoT;
- CoT 越长,性能越好;模型越大,提升斜率越陡:
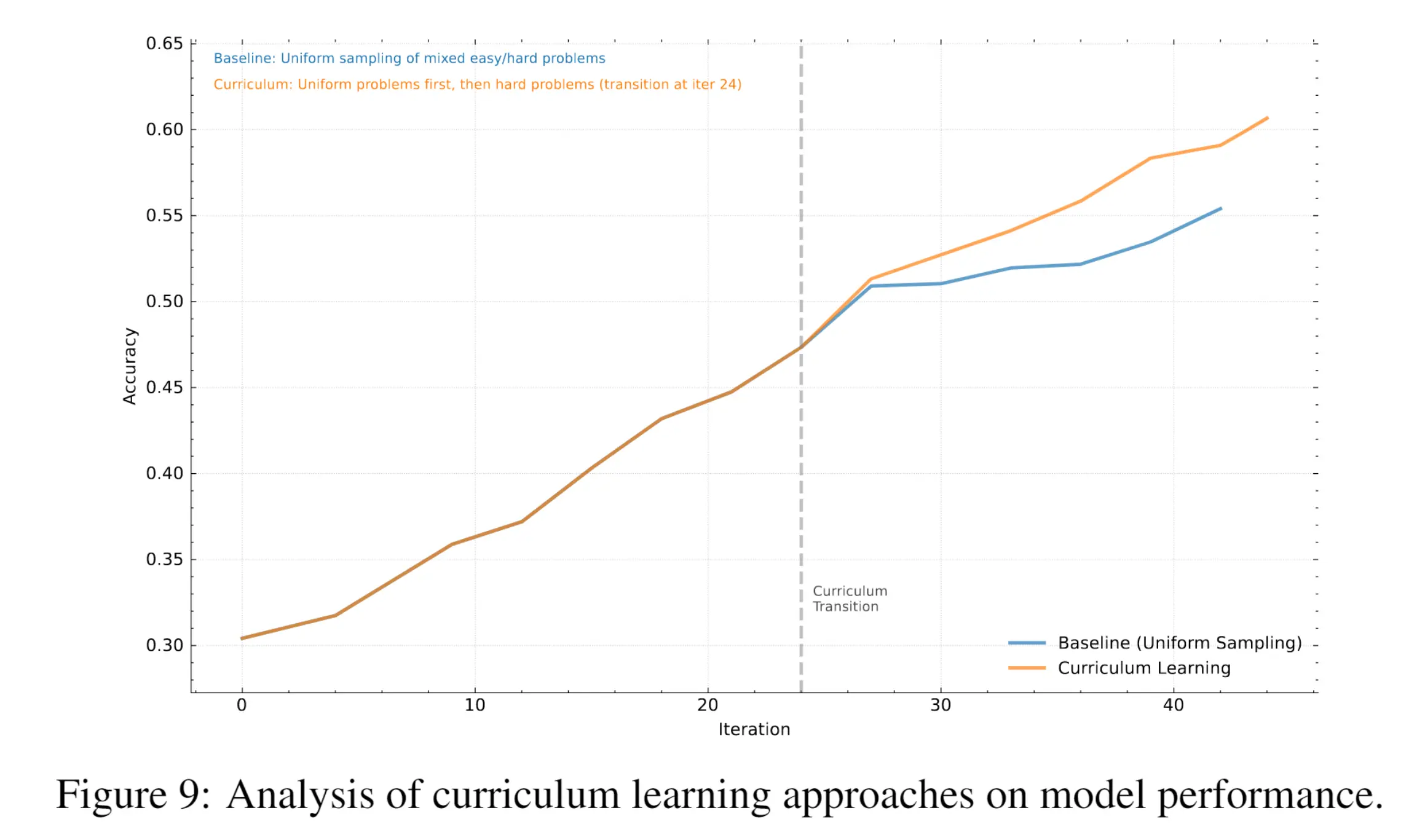
5.3 课程学习显著有效 #
- 固定难度训练(蓝线)快速饱和;
- 课程学习(橙线)持续提升:
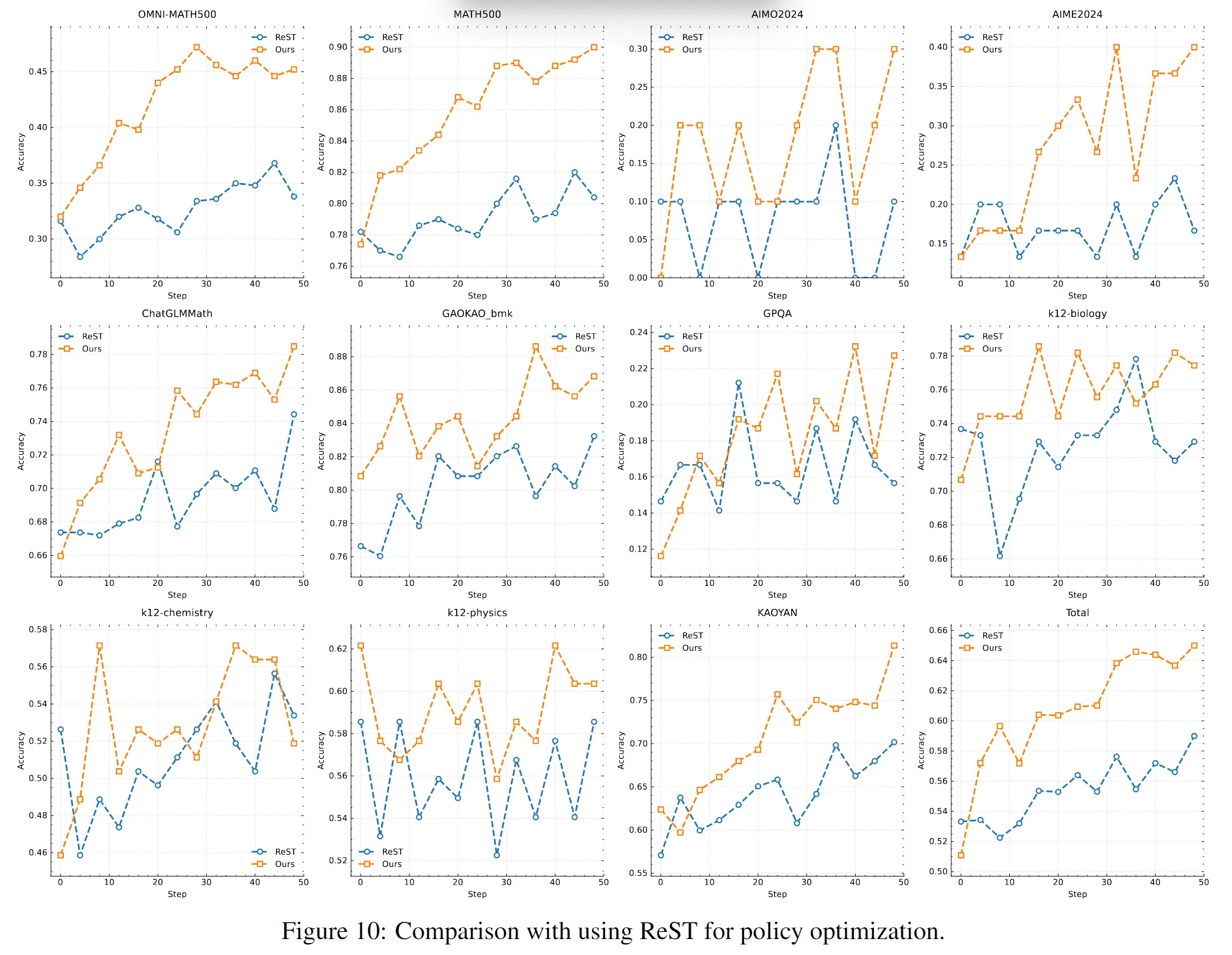
5.4 负样本梯度有用 #
- 对比 ReFT(仅用正样本)→ 含负样本策略表现更优:
✅ 总结:Kimi-K1.5 的三大工程可复用亮点 #
- RL 数据精筛三原则(多样+动态难度+可评估)——可直接用于自建 RL pipeline;
- Long2Short 迁移技术(尤其权重融合)——低成本部署轻量高能模型;
- 拒绝采样 + 优先采样 + 课程学习 组合拳 —— 提升训练效率与收敛质量。
作者:chaofa|全网同名
原文链接:https://yuanchaofa.com/post/kimi-k1.5-paper-reading-notes.html
如需导出为 PDF/PPT 或提取某部分细节(如代码测试生成流程),我可进一步整理。
参考 #
以下是对 《深度解读 Kimi-K1.5,真正了解 RL 数据是怎么筛选的》 的结构化摘要,保留原文关键图片与核心要点,便于快速把握 Kimi-K1.5 的技术亮点与工程实践细节。